the copy dataset selects 20 16-channel blocks that start 32 channels apart,
the maximum dataset will show maximum values in each 16-channel block
in every spectra.
Symbols:
These symbols will denote how the shape of the parent group's data field, ...
These symbols will denote how the shape of the parent group’s data field,
could be split into a left set of O outer dimensions, \(\boldsymbol{D}\),
and a right set of R region dimensions, \(\boldsymbol{d}\),
where the data field has rank O + R. Note O\(>= 0\).
The name of data field in the parent group or the path of a data field relativ ...
The name of data field in the parent group or the path of a data field relative
to the parent group (so it could be a field in a subgroup of the parent group)
The name of an optional mask field in the parent group with rank :math:`\bolds ...
The name of an optional mask field in the parent group with rank \(\boldsymbol{R}\) and
dimensions \(\boldsymbol{d}\). For example, this could be pixel_mask of an
NXdetector.
The starting position for region in detector data field array. ...
The starting position for region in detector data field array.
This is recommended as it also defines the region rank.
If omitted then defined as an array of zeros.
The number of blocks or items in the hyperslab selection. ...
The number of blocks or items in the hyperslab selection.
If omitted then defined as an array of dimensions that take into account
the other hyperslab selection fields to span the parent data field’s shape.
An optional field to define the block size used to copy or downsample data. In ...
An optional field to define the block size used to copy or downsample data. In the
\(i\)-th dimension, if \(\mathbf{block}[i] < \mathbf{stride}[i]\)
then the downsampling blocks have gaps between them; when block matches stride
then the blocks are contiguous; otherwise the blocks overlap.
If omitted then defined as an array of ones.
An optional field to define a divisor for scaling of reduced data. For example ...
An optional field to define a divisor for scaling of reduced data. For example, in a
downsampled sum, it can reduce the maximum values to fit in the domain of the result
data type. In an image that is downsampled by summing 2x2 blocks, using
\(\mathrm{scale}=4\) allows the result to fit in the same integer type dataset as
the parent dataset.
If omitted then no scaling occurs.
An optional group containing data copied/downsampled from parent group’s data. ...
An optional group containing data copied/downsampled from parent group’s data. Its dataset name
must reflect how the downsampling is done over each block. So it could be a reduction operation
such as sum, minimum, maximum, mean, mode, median, etc. If downsampling is merely copying each
block then use “copy” as the name. Where more than one downsample dataset is written
(specified with @signal) then add @auxiliary_signals listing the others. In the copy case,
the field should have a shape of \((D_0, ..., D_{\mathbf{O}-1}, \mathbf{block}[0] * \mathbf{count}[0], ..., \mathbf{block}[\mathbf{R}-1] * \mathbf{count}[\mathbf{R}-1])\),
otherwise the expected shape is \((D_0, ..., D_{\mathbf{O}-1}, \mathbf{count}[0], ..., \mathbf{count}[\mathbf{R}-1])\).
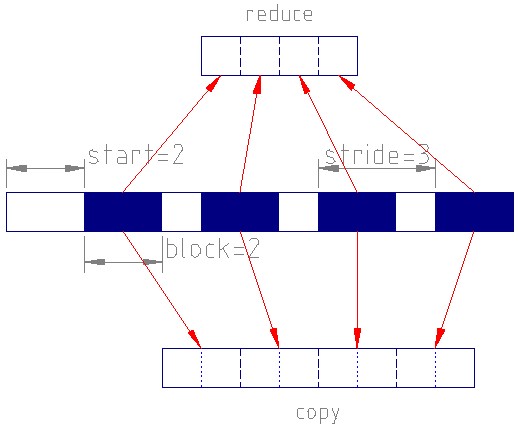
The following figure shows how blocks are used in downsampling:
A selection with \(\mathbf{start}=2, \mathbf{count}=4, \mathbf{stride}=3, \mathbf{block}=2\) from
a dataset with shape [13] will result in the reduce dataset of shape [4] and a copy dataset of shape [8].¶
An optional group containing any statistics derived from the region in parent ...
An optional group containing any statistics derived from the region in parent group’s data
such as sum, minimum, maximum, mean, mode, median, rms, variance, etc. Where more than one
statistical dataset is written (specified with @signal) then add @auxiliary_signals
listing the others. All data fields should have shapes of \(\boldsymbol{D}\).